High-Speed Cameras and Slow-Motion Video Terms and Concepts

High speed photography - water drops falling still image
High-speed photography may be defined as:
1) Photography of relatively fast-moving objects, taken in a way to reduce motion blur, or
2) A series of images taken at a high capture rate
The stock water drop image shown here satisfies the first definition. For this example, a strobe light was most likely used to freeze the motion, thereby catching the water droplet as it forms a coronet. It is interesting both because of its symmetrical beauty, and because it shows unexpected behavior in an otherwise mundane occurrence.
The slow-motion video effect, evident whenever the playback rate of a clip is slower than the capture rate, is an example of the second definition of high-speed photography. Often used in film making, it is a cinematic device that may be subtle or very pronounced. It may be used to gently set a mood, enhance drama, or accentuate the beauty of movement.
For technical applications it is more often used to help us see things that we would otherwise miss if we used the naked eye. Used as a troubleshooting device in manufacturing environments, it can help sort out the cause of an unexpected mechanical event, such as a paper jam in a rewinder or a missed cap on a bottling line. It may also be used to analyze animal, human, or robotic locomotion.
This horse racing video shot with a Fastec TS5 camera at Pimlico exemplifies drama and beauty in movement while it enables us to analyze the mechanics of locomotion and the interaction of horse and jockey:
High frame-rate digital imaging captured when using specialized high-speed cameras such as those from Fastec Imaging satisfies both definitions of high-speed photography. The Fastec IL5 images below were taken with a very fast shutter, creating a series of blur-free images much like those captured in still photographs using strobe illumination. A high frame rate is used to ensure every critical moment of the event is recorded. The imagery produced may be used to produce a short compelling video.
Sequences like this exemplify a very common use of high-speed cameras: the analysis of events that are too fast for the human eye to perceive.
The term pixel, derived from the words picture and element, is used to represent the smallest element of a digital image, one dot. The term may be used to describe three very different but related things:
- A high-speed CMOS sensor comprises millions of pixels on one integrated circuit, or chip. Each pixel is made up of five to seven tiny transistors and is capable of converting light into an electrical charge that is initially stored, then read out to an analog to digital converter to produce a digital image. In this case a “pixel” is a physical element in an electronic component.
- Once digitized, pixel values read out of the sensor may be stored in electronic memory or mass storage device as part of an image file, or transmitted for display, or some combination of both. Digitized pixels have numerical values such that dark areas of an image have low values and bright areas have higher ones. In this case a “pixel” is a numeric value that is stored on some sort of electronic media.
- Finally, the pixel values are converted back to visible light by the pixels of a digital display such as a computer monitor, television, cell phone, VR headset, etc. In the last case, the pixel is some sort of light or an array of lights, whether a minuscule element of a computer display or a light bulb in an enormous stadium display.
The image sensor is the heart of any digital camera. Many of the items discussed here are sensor specifications, among the most important of which are Resolution and Format.
The image sensor is an array of pixels, organized in columns and rows. The number of pixels in each column defines the horizontal resolution of the sensor, while the number of pixels in each row defines the vertical resolution. The most common unit used for comparing sensor resolution is the megapixel, or MP. A sensor with 1920 columns and 1080 rows has a total of 2,073,600 pixels and is considered a 2-megapixel sensor. 1920 x 1080 is a very common resolution used in broadcasting, also known as full HD. Other common sensor resolutions are 1280 x 1024 (SXGA), or 1.3MP and 640 x 480 (VGA), or .3MP. Larger than HD resolutions are increasingly sought after. Fastec’s IL5 and TS5 cameras, for example, have 5-megapixel sensors with 2560 columns and 2048 rows.
Sensor format, or optical format, is a term that is often used to describe the physical size of a sensor. Many high-speed cameras utilize c-mount lenses that were initially designed for film and CCTV cameras. Common C-mount lens formats include 2/3-inch, 1-inch, and 4/3-inch. The 2/3-inch sensor has a diagonal of up to 11 millimeters while the 1-inch sensor has a diagonal of 16 millimeters, and the 4/3-inch has a diagonal of about 23 millimeters. Micro four thirds, or M43 lenses, which have become very popular on “mirror-less” SLR cameras, also have a diagonal of about 23mm.
Full format sensors, which are relatively uncommon in the high-speed world, have sensor diagonals the same size as 35mm film, or about 42mm. Nikon F-mount and Canon EF-mount lenses.
A lens that works properly on a camera having a small sensor may not produce a large enough image circle to work correctly on a camera having a larger sensor. The area used on a given sensor also changes with resolution. A sensor capable of 1920 x 1080 resolution with a 2/3-inch sensor (11mm diagonal) will only use about an 8mm diagonal when recording at 1280 x 720. For sensor/lens compatibility for Fastec cameras, get the Fastec Camera Calculator. There is Lens Tutorial available as well.
Sensors, and sometimes images may be referred to as 8-bit, 10-bit, 12-bit, etc. This is a reference to the number of binary digits used to express pixel values. The more bits, the greater number of values, and the greater number of shades that may be represented by each pixel.
For Monochrome (grayscale) cameras:
- 1- bit pixel has 21 (2) values (black and white)
- 2- bit pixel has 22 (4) values (black, two intermediate shades, white)
- 3- bit pixel has 23 (8) values
- 8-bit pixel has 28 (256) values
- 10-bit pixel has 210 (1024) values
- 12-bit pixel has 212 (4096) values
For color cameras, each pixel on the sensor will have the same number of values in relation to bit-depth as mono cameras. But each pixel will also have a single-color filter, red, green, or blue, physically applied to it. A green 8-bit pixel, for example, will have 256 green values.
Raw, (non-compressed, non-color-interpolated) image files from color cameras also maintain these same number of values per pixel.
RGB processed color images from color cameras are given 3 values from each pixel, red, green, and blue, which are calculated (interpolated) using values from surrounding pixels. RGB images, thus, have a greater number of shades possible for each pixel, according to bit-depth:
- 1- bit has 21 (2) “raw” values and 23 (9) colorized values
- 2- bit pixel has 22 (4) “raw” values and 43 (64) colorized values
- 3- bit pixel has 23 (8) “raw” values and 83 (512) colorized values
- 8-bit pixel has 28 (256) “raw” values and 2563 (16,777,216) colorized values
- 10-bit pixel has 210 (1024) “raw” values and 10243 (1,073,741,824) colorized values
- 12-bit pixel has 212 (4096) “raw” values and 40963 (68,719,476,736) colorized values
Most “colorized” image file formats and display devices are limited to 8 bits/pixel. The relevance of recording in pixel depths higher than 8-bit is that the “extra” bits may be used to great advantage for enhancing image quality during processing. In order to take advantage of higher bit depths, images must be stored in supporting file formats such as TIFF raw and DNG.
Frame rate, sample rate, capture rate, record rate and camera speed are interchangeable terms. Slow motion video is created when the frame rate, usually expressed in frames per second or “fps” of a recording is greater than the playback rate, also expressed in fps. For example, if a camera records at 300fps and the resultant clip is played back at 30fps, there is a 10x slow motion effect. To put this into perspective, slow motion sports clips on TV are most often played at rates between 4x and 8x.
High recording frame rates are a defining characteristic of high-speed digital imaging. For most technical applications the ideal frame rate is determined by calculating how quickly objects of interest will be moving within the field of view. To compute this, one must consider the absolute speed of the object vs. the field of view. The field of view of the camera is dictated by its magnification, which is a function of the object distance, sensor area used, and lens focal length. Frame rate requirement is dependent on magnification as well as object speed. For a more complete discussion of these relationships, please refer to our Fastec Presentation “Magnification and Frame Rate.”
Setting up a high-speed shot, like any in photography, is an exercise in balancing options. Frame rate and resolution are often the best place to begin. High-speed digital cameras are generally capable of higher frame rates at lower resolutions. The decision to be made is whether to opt for a larger resolution and perhaps a larger field of view at a slower frame rate, or a smaller resolution and perhaps a smaller field of view with a higher frame rate.
Another related option to balance is record time. High-speed cameras are capable of producing vast amounts of image data in short periods of time. Too low a frame rate may result in missing the required detail of an object’s behavior, while too high a frame rate may result in higher storage requirements than necessary.
Maximum Resolution (max vert-res x max horiz-res) x Maximum fps (@ max resolution)
Thus, if the maximum resolution is 1280 x 1024 and the maximum frame rate at that resolution is 1000fps, then the maximum pixel rate is: 1280 x 1024 x 1000, or 1,310,720,000 pixels/sec, or 1,311Mp/sec.Most high speed digital cameras have global electronic shutters, where “global” refers to the design where all pixels begin and end their light-to-charge functions in unison. This is a very specialized operation and is one of the ways the bona-fide high-speed camera is very different than a standard video camera with slow motion features. It requires a more complex pixel design whereby immediately following integration (exposure) the charge on each pixel is transferred to a non-light-sensitive structure within the pixel where it is held until it can be read, thereby freeing the pixel to begin integration for the next frame.
Most digital cameras use “rolling” electronic shutters whereby pixels are read off immediately after exposure but are not all read simultaneously. This means that actual time of the exposure is not the same for the frame and any movement that has occurred as the sensor is being read may show progressively across every image.

Still photograph of a fan taken with an iPhone - the fan blades appear blurry

Same still photograph taken with a Fastec IL5 with a 60-microsecond shutter
The classic image comparison between global and rolling shutters are pictures of fan blades in which the blades appear to shift to one side of the fan. The image to the left was taken with an iPhone, while the image on the right was taken with a Fastec IL5 with a 60-microsecond shutter. Both the fan and the wheel were rotating at the same speeds in both images and the same illumination was used.
For a standard movie camera, the movement across the field of view is expected to be slightly blurred to give it a realistic look on screen. After all, the moving picture is really a series of still images projected quickly enough to trick the eye. Movie cameras often use the term “shutter angle” for shutter controls, going back to the days when the shutter was a rotating disk, synchronized to rotate 360⁰ with each frame. The operator would set the angle for which it would open to expose the film. The normal setting was 180⁰, meaning that the exposure time would be 1/2 the interval of the frame rate. This setting was chosen as it gave the most natural look. Smaller angles were used to add intensity to the motion for action scenes.
For motion analysis purposes, however, it is better to have a crisp and clear non-distorted image for frame-by-frame review. To do this, the exposure often needs to be quite short to ensure that the object of interest does not move much during the exposure, causing motion blur.
You can calculate motion blur if you know the speed at which an object is moving, the dimensions of the field of view, the pixel resolution, and the duration of exposure. The frame rate is not important. For example, if an automobile is traveling at 30mph across a field of view that is 50 feet across at a horizontal resolution of 1920 with a shutter duration of 100 microseconds:
- We can compute how far the car will travel during the shutter time of 100ms,
• 30mph = 44 feet/sec. 100ms is .0001 seconds, so the car goes .0044 feet in 100ms - and then how far in relation to the field of view, 50feet
• .0044/50 = .00088 - and then how many pixels of the 1920 across the image does that represent:
• .00088 x 1920 = 1.68
The motion blur in pixels is, thus, about 2 pixels. This number is directly proportional to the shutter duration, so a 1millisecond shutter would yield 16.8 pixels of blur. The acceptable amount of blur depends on the size and complexity of the object to be tracked and the accuracy required.
The IL5 image, below to the right was taken of a 4” 50Hz fan with a 60ms shutter. It has extremely little motion blur compared with the iPhone image to the left.
Still photograph of a fan taken with an iPhone - the fan blades appear blurry
Same still photograph taken with a Fastec IL5 with a 60-microsecond shutter
Exposure in a digital camera system can be defined as the amount of light used for each frame. There are three factors that affect exposure:
1) Illumination, which consists of the source of light projected onto the sensor, reflected by or emitted from the object to be imaged
2) the transmittance of the lens, which can be controlled by adjusting the lens aperture
3) the integration or “shutter” time of the camera, which is the length of time the sensor is actually collecting light for each frame.
The ideal exposure for any image sensor is dependent on its light sensitivity and remains a constant at any given level of gain. Generally, image quality, especially with respect to noise and dynamic range, are adversely affected as gain is added.
There are trade-offs as well with the mentioned factors for affecting exposure:
- Adding or adjusting illumination is often necessary to get the best images. This has been elevated to an art for serious photography and movie making. The balance here is one of effort. Proper illumination of a scene can be a painstaking process for which there may not be the time or will. There are many applications for which adding enough light to facilitate getting an ideal exposure is not possible.
- Adjusting lens aperture affects Depth of Field, DOF, which is the depth to which objects will appear in focus. As a lens is “stopped down” to transmit less light, the DOF increases, which is usually beneficial for high-speed shots. Conversely, the more open the aperture is, the shallower the DOF becomes. For more information please refer to the tutorials DOF calculator and DOF vs Pixel Size.
- Adjusting the shutter duration affects the exposure. The maximum exposure for any given frame rate is an interval slightly less than 1/frame rate. When imaging objects that are moving quickly through the field of view, it is often necessary to reduce the shutter duration to minimize motion blur. The amount of motion blur that is tolerable for a given application is dependent on the shape of the object to be imaged and the clarity required to analyze its behavior.
Storage Space / ((Horizontal Resolution) X (Vertical Resolution) X (bit depth) X Frame Rate))
There are some caveats:
- Not all storage media can record the full bandwidth of the camera
- There is some small amount of metadata saved with each file. This is practically negligible for megapixel images, but as the image size decreases, the metadata becomes an increasingly important factor.
Most cameras are simply triggered whenever an image is to be captured. For example, with a still camera, the shot is composed, the photographer waits for the right instant and then triggers the camera by pressing the shutter button or a remote switch. For a video camera, a trigger is sent to begin recording, then another is sent to end it.
High speed events, however, may occur too quickly for the photographer to respond. One strategy to ensure capturing a high-speed event is to begin recording well before the event is expected and continue recording until the event has occurred. The problem with this strategy is that because of the high frame rates, the amount of video that is saved may be very extensive. There may not be enough memory to store it all, or it may produce much more data than can be reviewed.
The most common way to accommodate this triggering issue in a high-speed camera is with the use of a circular buffer and what we call an “end” trigger. The
circular buffer is set to record some amount of video, usually in seconds, but much longer intervals are possible when recording to an SSD. The buffer will record a preset period of time, then begin writing over the oldest images while preserving new ones. For example, the buffer could be set to record for 10 seconds before it “wraps”. When the camera gets a trigger, it simply stops recording. If a trigger can be sent to the camera within 10 seconds of the event, it will be captured.
Often video from both before and after an event may be useful. In this case we can move the trigger position to any spot in the buffer we want. Using the above example with a trigger set for 50% of the buffer, we would always record 5 seconds before and 5 seconds after a trigger.
Human vision comprises of electromagnetic waves between about 400 and 700 nanometers in length. Starting with 700nm and working backwards, we have the colors of the rainbow: red @ 600-700nm and violet @ 400nm, with orange, yellow, green, and blue in between. The peak human response to light is at about 550nm, which is in the middle of the green band, as seen on this response curve.
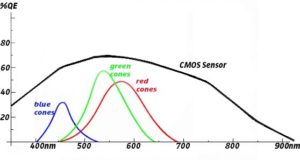 Notice the curves for red, green, and blue cones. These three types of photo receptors give us our ability to see up to about 10,000,000 hues, although some of us have much greater color acuity than others. There is a much wider disparity among animals. Some have up to 15 different types of photo receptors, usually for highly specialized narrow bands, while other animals are considered color-blind.
Notice the curves for red, green, and blue cones. These three types of photo receptors give us our ability to see up to about 10,000,000 hues, although some of us have much greater color acuity than others. There is a much wider disparity among animals. Some have up to 15 different types of photo receptors, usually for highly specialized narrow bands, while other animals are considered color-blind.
CMOS sensors used for most digital cameras are sensitive to a wider band than humans and most animals, generally from about 300nm to 900nm, as depicted by the black line on the response curve, above.
This discrepancy in the response of camera sensors vs human and animal sight poses opportunities as well as challenges.
The greatest opportunity comes in the form of using mono cameras with illumination in the Near Infra-Red (NIR) for applications that require intense illumination, but cannot disturb test subjects. Many studies of zebra fish, bats, some insects, etc. are done using this technique as these animals are not sensitive to NIR.
More challenging is the reproduction of color by the camera. This is basically a three-step process:
- A filter to eliminate light outside the visible spectrum is placed between the lens and the sensor. This is usually an IR cut filter, which limits light above 650nm. It is necessary because, while there is often a lot of light present in this range, humans are blind to it, so it cannot be used when we are trying to replicate the human experience. An example of this is that there is often a great deal of NIR reflected by certain foliage. Without the IR cut filter a deep green tree might appear to be bright red to the camera!
 A Bayer filter mosaic is applied to color sensors. The Bayer filter mosaic or color filter array, CFA, is the placement of a red, green, or blue filter atop each pixel of the sensor. These are arranged in green/ blue/green and red/green/red rows, such that 1/2 of all pixels are green, 1/4 are red and 1/4 are blue. In this way each pixel responds only to the band of illumination that is roughly equivalent to what the red, green, and blue cones of the human eye would see.
A Bayer filter mosaic is applied to color sensors. The Bayer filter mosaic or color filter array, CFA, is the placement of a red, green, or blue filter atop each pixel of the sensor. These are arranged in green/ blue/green and red/green/red rows, such that 1/2 of all pixels are green, 1/4 are red and 1/4 are blue. In this way each pixel responds only to the band of illumination that is roughly equivalent to what the red, green, and blue cones of the human eye would see.- Color interpolation is done on a per-pixel basis to render red, green, and blue, values for each. For each pixel, its value as well as the values of surrounding pixels of other colors are used to yield these “RGB” values.
While some cameras use multiple sensors, each with its own color filtration, for the creation of color, and some sensors have the ability to collect RGB data on a per-pixel basis, the vast majority of color digital cameras use the above techniques. There are some obvious negatives when using color vs. mono cameras:
- Almost half of the light to which the sensor is responsive is eliminated by the NIR cut filter. And for each pixel, much of the remaining light outside its own color band is eliminated. This usually results in color cameras having less than 1/2 the sensitivity of mono cameras, depending on the illumination spectrum.
- Interpolation algorithms are optimized for daylight. While there is high-quality white and daylight balanced artificial illumination available, getting good color reproduction in most artificial lighting is a challenge.
- In order to produce RGB values for each pixel, the surrounding pixels must be used, which means that the spatial resolution for the color camera is not as fine as that of the mono camera. That is not to say that extremely sharp color images are not possible, but mono images are generally sharper.
- High contrast edges, will not yield fine enough color information for the interpolation algorithms to resolve, resulting in color aliasing. For example, you will often see red, green, and blue smudges in images of black and white text.